
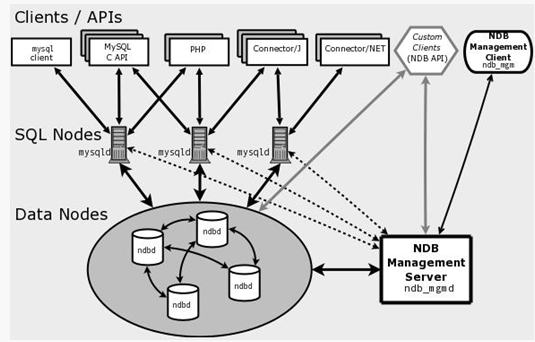
一、介绍
复制(Replication)是用以从源实例(主库,master)拷贝数据到目标实例(从库,slaves),使用的是MySQL自身的binlog文件进行,binlog记录了源实例的数据变更情况,以此在目标端回放,从而达到数据一致的效果(所以若需要进行复制,必须开启源端实例的binlog)。
默认情况下,Replication默认是异步复制,即binlog是异步复制到目标实例的,slaves的状态不会影响到master;此外,MySQL也提供了半同步复制(Semisynchronous Replication):即master上的事务,需要等到至少一个slave确认收到事务的所有events,才能勾提交成功,否则会超时失败。MySQL在部分场景下支持“全同步复制”:即所有slaves写盘成功后,master才能提交成功,例如MySQL Cluster,但是“完全同步复制”会阻塞master,严重影响性能,依赖网路。
MySQL Cluster中存储引擎为NDB(Network Database),在实例环境中较少用到,用得更多的是InnoDB,因此官方也有对于InnoDB的集群方案—-InnoDB Cluster。
除了使用binlog中的file名称和位点信息进行顺序复制外,MySQL提供基于GTIDs(global transaction identifiers)的复制方式:即在集群中,GTID是唯一的,由于每个事务的GTID都不相同,这使得在事务的追溯,或是新增slave、master实例的fail over宕机切换等方面变得简单。
二、常见集群架构
2.1 一主一从
即一个主库一个从库,是最为常见的集群架构。一主一从结构简单,常在很多环境进行使用,例如读写分离、数据库备份等。
2.2 一主多从
一个主库多个从库,多个从库可以提供给不同的应用方,例如业务方使用一个从库,大数据的离线任务使用另一个。
2.3 多源复制
把多个主库的数据复制到同一个从库,通常作为数据的备份归档使用。
2.4 级联复制
即从库作为另一个实例的主库,A复制到B,B复制到C。为了防止主库上的复制压力过大,例如主库上已经有3/4个从库了,若继续添加,会导致主库的性能有所下降(复制也是需要消耗硬件资源的,例如网络带宽),而若是半同步,则影响会更为明显,所以可以用级联复制的方式,减轻主库的负担。
2.5 组复制
Group replication(https://dev.mysql.com/doc/refman/8.0/en/group-replication.html),是MySQL官方通过插件形式(plugin)提供的高可用容错的复制拓扑结构。简单来说就是把多个MySQL的实例,组成一个集群,共同向clinets提供服务,以减轻单点的负担,同时还能提供高可用,在master故障时候,使用其它的节点提供master的服务。由于涉及到的内容过多,后续会详细介绍。官方文档甚至单列了一章来介绍Group Replication。

2.6 双主复制
双主复制,其实是两个实例互为主从,可以调整自增值、步长等配置,使两端的实例能够正常运行,但是在实际环境中,双主容易出现数据不一致的情况。
三、Replication的主要功能:
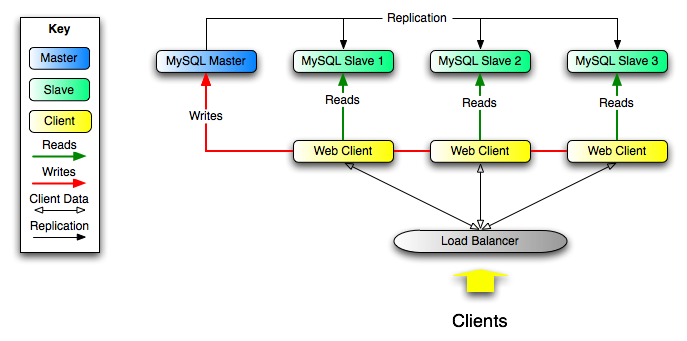
3.1 横向拓展/降低主库负载
部分对于延迟要求不高的查询,或是较为复杂的统计分析累查询,可以放在从库进行,以降低这类查询对于主库的影响。如下图所示,master主要负责“写”操作,其它的从库,则分担不同的读查询。
3.1 用以备份
在异步复制中,从库的状态不会影响到主库,所以我们可以使用mysqldump或者是xtranbackup等工具,在从库上备份数据,防止备份过程影响到主库。
3.2 从库使用不同的表结构
由于复制是不区分目标和源的部分状态的(即只要binlog中的SQL能够正常回放即可)。所以,从库上可以建立不同的索引,甚至是使用不同的存储引擎,以适应需要在从库上进行查询的业务。
3.3 数据库拆分
通常在业务上线前期,部分量小的数据库,会被放在同一个实例中,但是随着数据量或者QPS的升高,需要将其中的数据库进行拆分,就可以使用复制Replication,将不同的数据库,复制到不同的实例中。可以使用–replicate-wild-do-table=databaseA.%进行数据库、表的过滤。
3.4 高可用
复制可用以把master复制到另一个实例,当master意外宕机时,立即切换到新的实例上,从而降低对于业务的影响。这其中有数据一致性的相关要求,例如半同步复制中的:lossless replication,即无损复制,从5.7.2版本开始加入,相关配置为:rpl_semi_sync_master_wait_point,具体可参考:http://codercoder.cn/index.php/2019/09/mysql5-7-lossless-semi-replication/
3.5 延迟复制
即人为让从库产生多长时间的延迟,通过CHANGE MASTER TO MASTER_DELAY = N;进行指定。作用:
(1)若主库上产生误操作,可以及时使用正常数据的从库进行恢复
(2)测试延迟对于某些业务功能的影响
(3)可以在从库上看到历史的数据
参考:https://dev.mysql.com/doc/refman/5.7/en/replication-delayed.html
实际环境中,复制还有许许多多的使用方式,例如搭配着多源复制和延迟复制,进行数据的备份,除了能恢复误操作的数据,一个实例存放多个源实例的数据备份,还能节省成本;使用lossless半同步复制,能够让我们的高可用环境数据一致性得以更好的保证,降低了数据不一致的风险等等……
而只要是涉及到MySQL的迁移、同步等等,均是基于复制进行的,所以需要深刻了解复制的过程,发挥其最大的作用。
欢迎关注公众号:朔的话:
