
背景
Otter是阿里巴巴公司的开源项目,用以进行多机房数据库同步。对于其数据一致性,开源版解决方案为:单向回环补救。1
单向回环补救概况
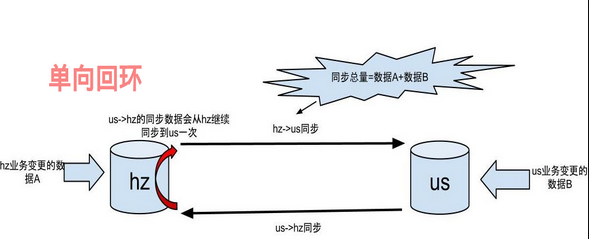
在双向同步时,例如AB双向同步,在Otter中设置A为主站点,B为非主站点,则:
A产生的数据,只会从A—->B,回环终止,保证不进入死循环
B产生的数据,从B—->A,会再次进入到A—->B的回路,形成一次单向的回环
存在的问题:存在同步延迟时,会出现版本丢失高 / 数据交替性变化
1. 对于B同步到A,先从B—->A,变更很快完成,但是此时在A中产生了很大的数据变更,则A—->B的链路又会回放一次,导致出现数据交替
2. A同一条数据进行了十次变更(即产生10个版本),A很快同步到B,但是B对该行的操作需要进行回环,所以B在该行的数据—->A—->B时,会覆盖之前的10个版本
对于以上的两种问题,Otter官方给出了相应的解决方案:
- 反查数据库同步 (以数据库最新版本同步,解决交替性,比如设置一致性反查数据库延迟阀值为60秒,即当同步过程中发现数据延迟超过了60秒,就会基于PK反查一次数据库,拿到当前最新值进行同步,减少交替性的问题)
- 字段同步 (降低冲突概率)
- 同步效率 (同步越快越好,降低双写导致版本丢失概率,不需要构建冲突数据KV表)
- 同步全局控制 (比如HZ->US和US->HZ一定要一起启动,一起关闭,保证不会出现一边数据一直覆盖另一边,造成比较多的版本丢失)1
遇到的问题
在测试阶段,应用出现的问题(双向同步,A为主站点):
1. 在B端对某行进行了多次变更(即产生了多个版本),则数据会同步到A,继而再同步回到B
2. 业务在update后,马上进行查询,但是在查询时(同步会由A再回到B),查询到了一个中间状态的版本,此时应用报错
How to repeat?
首先看一下环境:
MySQL版本:5.7.22
A和B为两个机房的MySQL数据库,并且使用Otter进行双A同步,即两边均可写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
mysql> show create table test2 \G
*************************** 1. row ***************************
Table: test2
Create Table: CREATE TABLE if not exists `test2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(30) DEFAULT NULL,
`status` tinyint(4) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8
mysql> select * from test2;
+----+------+--------+
| id | name | status |
+----+------+--------+
| 1 | aaa | 0 |
| 2 | aaa | 0 |
+----+------+--------+
2 rows in set (0.00 sec)
mysql> **update test2 set name=concat(name,'x'),status=5 where status=0;select sleep(0.038); update test2 set name=concat(name,'y'),status=99 where status=5;update test2 set name=concat(name,'z'),status=100 where status=99;**
Query OK, 2 rows affected (0.01 sec)
Rows matched: 2 Changed: 2 Warnings: 0
+--------------+
| sleep(0.038) |
+--------------+
| 0 |
+--------------+
1 row in set (0.04 sec)
Query OK, 2 rows affected (0.00 sec)
Rows matched: 2 Changed: 2 Warnings: 0
Query OK, 0 rows affected (0.01 sec)
Rows matched: 0 Changed: 0 Warnings: 0
mysql> select * from test2;
+----+-------+--------+
| id | name | status |
+----+-------+--------+
| 1 | aaaxy | 99 |
| 2 | aaaxy | 99 |
+----+-------+--------+
2 rows in set (0.00 sec)
**此时出现数据版本丢失的情况**
**此时出现数据版本丢失的情况**
**此时出现数据版本丢失的情况**
由于中间版本的不稳定性,测试多遍,还有可能出现不同的结果:
1
2
3
4
5
6
7
8
9
10
11
<br></br>......
mysql> select * from test2;
+----+------+--------+
| id | name | status |
+----+------+--------+
| 1 | aaax | 5 |
| 2 | aaax | 5 |
+----+------+--------+
2 rows in set (0.00 sec)
解决思路
1. 数据合并概念
需要说明Otter的一个核心算法:数据合并2
数据合并算法
入库算法采取了按pk hash并行载入+batch合并的优化
a. 打散原始数据库事务,预处理数据,合并insert/update/delete数据(参见合并算法),然后按照table + pk进行并行(相同table的数据,先执行delete,后执行insert/update,串行保证,解决唯一性约束数据变更问题),相同table的sql会进行batch合并处理
.
b. 提供table权重定义,根据权重定义不同支持”业务上类事务功能”,并行中同时有串行权重控制
- 业务类事务描述:比如用户的一次交易付款的流程,先产生一笔交易记录,然后修改订单状态为已付款。用户对这事件的感知,是通过订单状态的已付款,然后进行查询交易记录。
.所以,可以对同步进行一次编排: 先同步完交易记录,再同步订单状态。(给同步表定义权重,权重越高的表相对重要,放在后面同步,最后达到的效果可以保证业务事务可见性的功能,快的等慢的. )
2. 添加表权重
从某种程度上说,可以通过设置不同表的权重,从而使相同表的变更合并在一起,可以降低风险。
但是,表的权重算法仅在入库时进行,而不是在拉取数据时,而若update是被分库在多个batch中,则权重并不能生效。
3. 关闭主站点
关闭主站点会导致并发时,两边数据不一致的情况,不能关闭主站点。
- 目前的思路并没有能解决问题,所以想要继续挖究,后续若有解决方案,再进行更新~
- .
数据一致性检验
批量检验
MySQL Ultility中的mysqldbcompare 工具
增量对比:
由于主键是单调递增的,所以可以在同步的过程中,进行校验,例如A和B双向同步,在某端产生了id > 0 and id 0 and id < 100的数据,进行比对