
一、基本情况
随着数据量的增多,往往带来数据库的负载加大,有时甚至会影响线上的正常业务,在此情况下,常有几种解决方案:数据归档、配置升级、数据拆分。对于数据库表的拆分,又分为:垂直拆分、水平拆分。
垂直拆分:将不同业务需要访问到的库,分在不同的数据库实例下,以降低单个实例的负载
水平拆分:常见两种方案:分库不分表、分库加分表
(图片来源https://www.digitalocean.com/community/tutorials/understanding-database-sharding)
数据归档:对于数据量或QPS较为稳定,不会“爆棚式”增长的库表,还有可能是公司内部难以推动或者关联较多导致拆分的环境,而可以采用的临时解决方案。
升级配置:将数据库所在的硬件设施进行升级,以便于更好的支撑当前的数据环境
由于数据归档、升级配置两种方案的思路很简单,不过多介绍,这里就说一些注意事项:
(1)数据下游
若下游有数据订阅,或者离线的任务,那么:
数据归档:部分业务可能会存在离线任务,那么离线任务的时间需要和归档时间错开,防止造成较高的负载;
订阅任务:需要判断是否需要过滤归档产生的DELETE语句(归档产生的DELETE的量可能会随数据量的大小,而变得很大,影响订阅的通道,造成订阅阻塞或者延迟较大的影响)
实例配置升级:大部分情况,进行实例配置的升级,涉及到新老实例的切换,会影响binlog的位点,在切换后,更改订阅的binlog的位点信息
所以下游有订阅任务时,需要进行调整切换的时间,应错开离线、归档任务
(2)数据归档注意事项查阅:MySQL手记11 — MySQL归档工具:pt-archiver
(3)配置升级可参考:MySQL手记14 — 数据迁移注意事项
二、数据库拆分
2.1 垂直拆分
将不同业务所需要访问的库表进行拆分,不同的业务访问不同的库表,访问其他业务的数据库表,则通过程序接口调用方式进行。
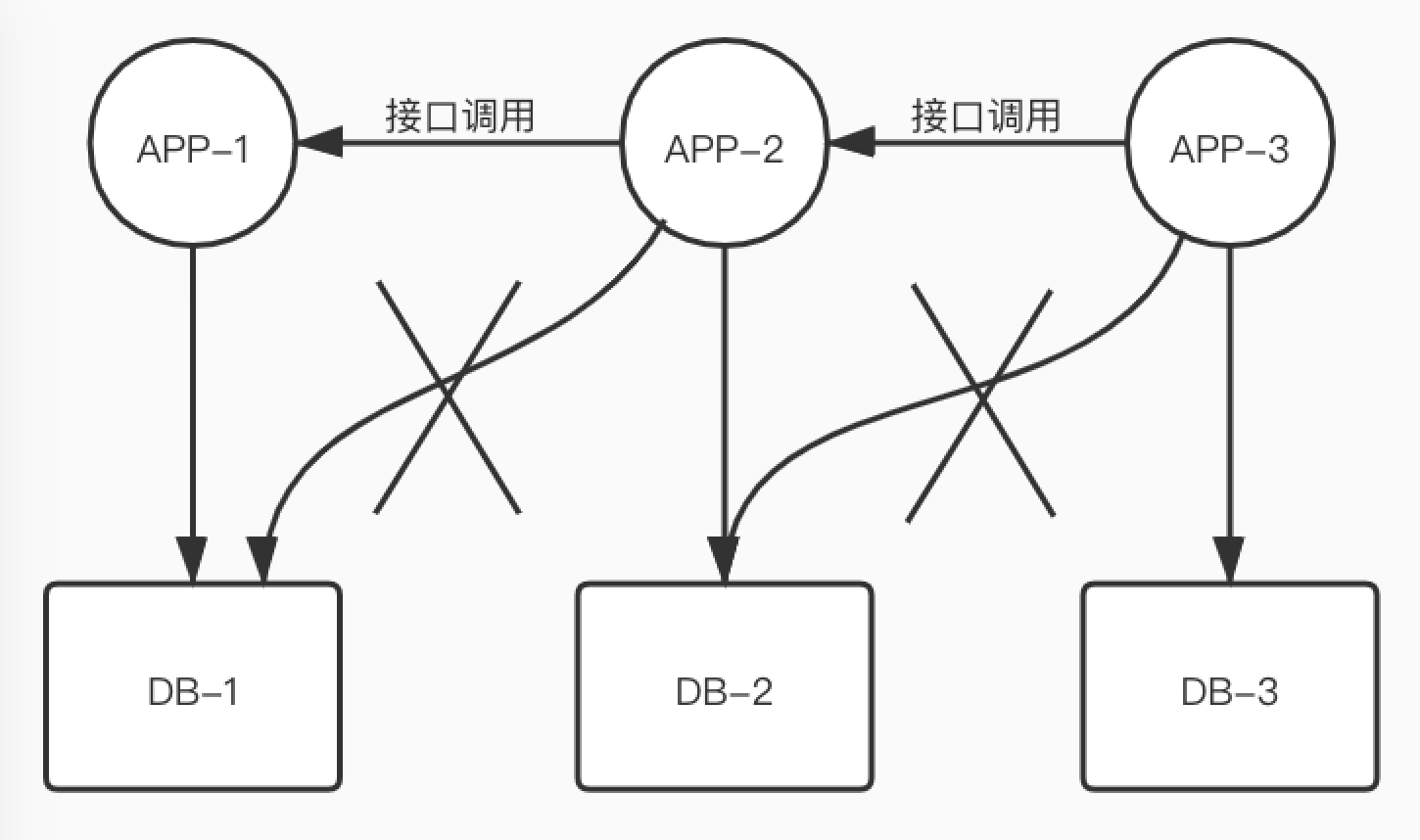
2.2 水平拆分
1. 仅分库
例如,应用A访问db1库的db1表,此时将db1拆分为16个库:db1_0 ~ db1_15,每个库中仅有一个同名表tb1。应用则通过分库的规则访问到不同的数据库实例。
2. 分库分表
例如,应用A访问db-1,此时将db1拆分为16个库16个表:db1_0 ~ db1_15,每个数据库中有16个表:tb0 ~ tb15。应用则通过分库分表的规则访问到不同的数据库实例下的不同表。
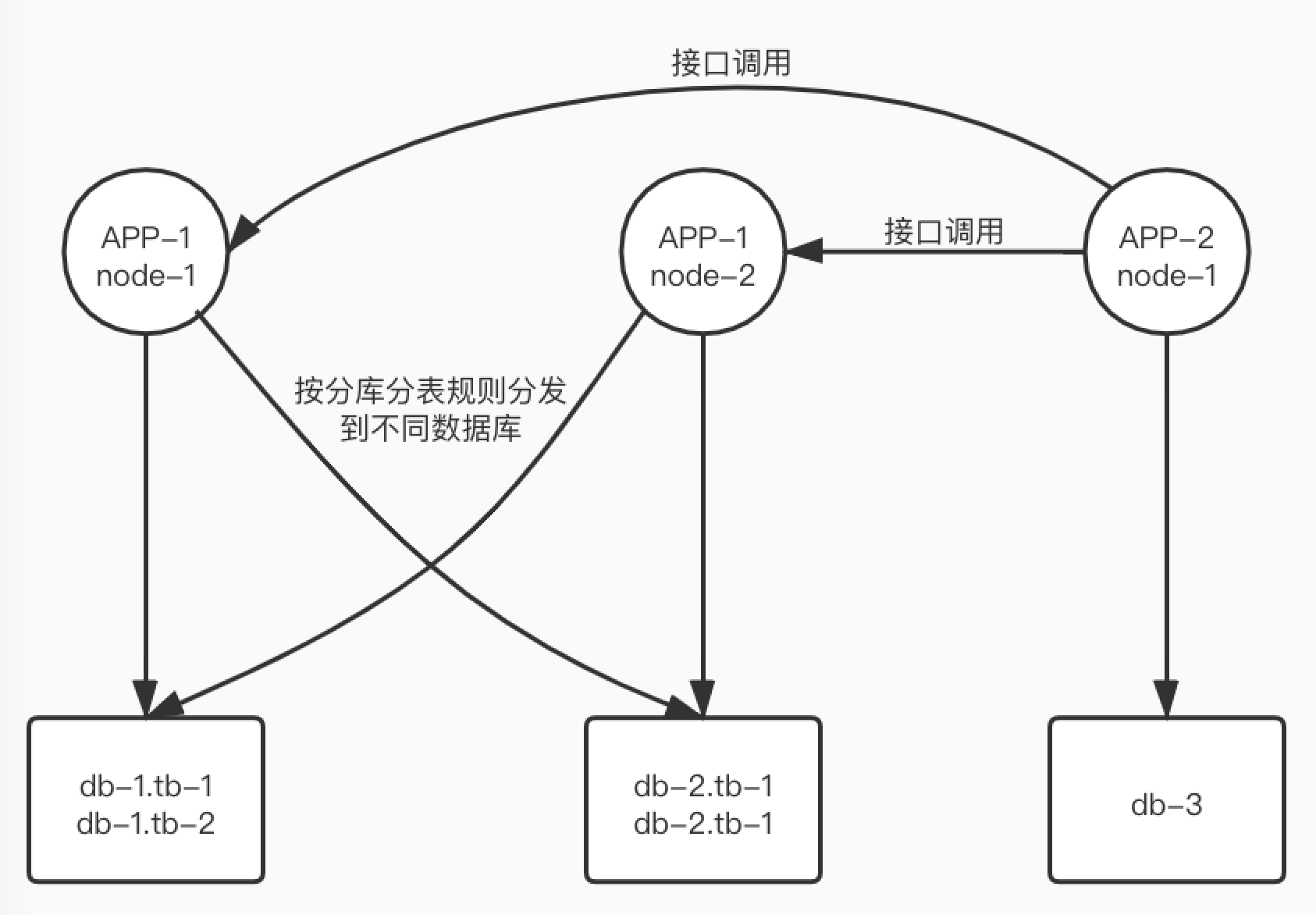
3. 仅分库 or 分库分表?
(1)数据量、QPS是否会大幅度上升?
数据量、QPS上升,业务量飞速上涨,以至于实例升配等的方案很有可能在短期内出现硬件的瓶颈,所以需要提前将数据库表进行拆分。
(数据库巡检:通常我们会对数据库进行巡检。每个一段时间,统计各个数据库大表信息,讨论是否需要进行拆分处理。)
(2)当前是否出现查询缓慢的瓶颈?
对于出现慢查的环境,DBA因首先进行SQL或者结构的优化,尽量降低慢查数,使当前的配置能够尽可能支撑更多的查询。
(3)业务对于响应速度的要求?
部分边缘的业务,哪怕是数据量很大,但是由于其对数据库的响应速度要求不高,需要根据需求判断。
三、分表分库
3.1 拆分前准备工作
对于数据库来说,做拆分之前一定要做足充分的准备,再拆分迁移后,分表分库的环境是很难进行回滚的。
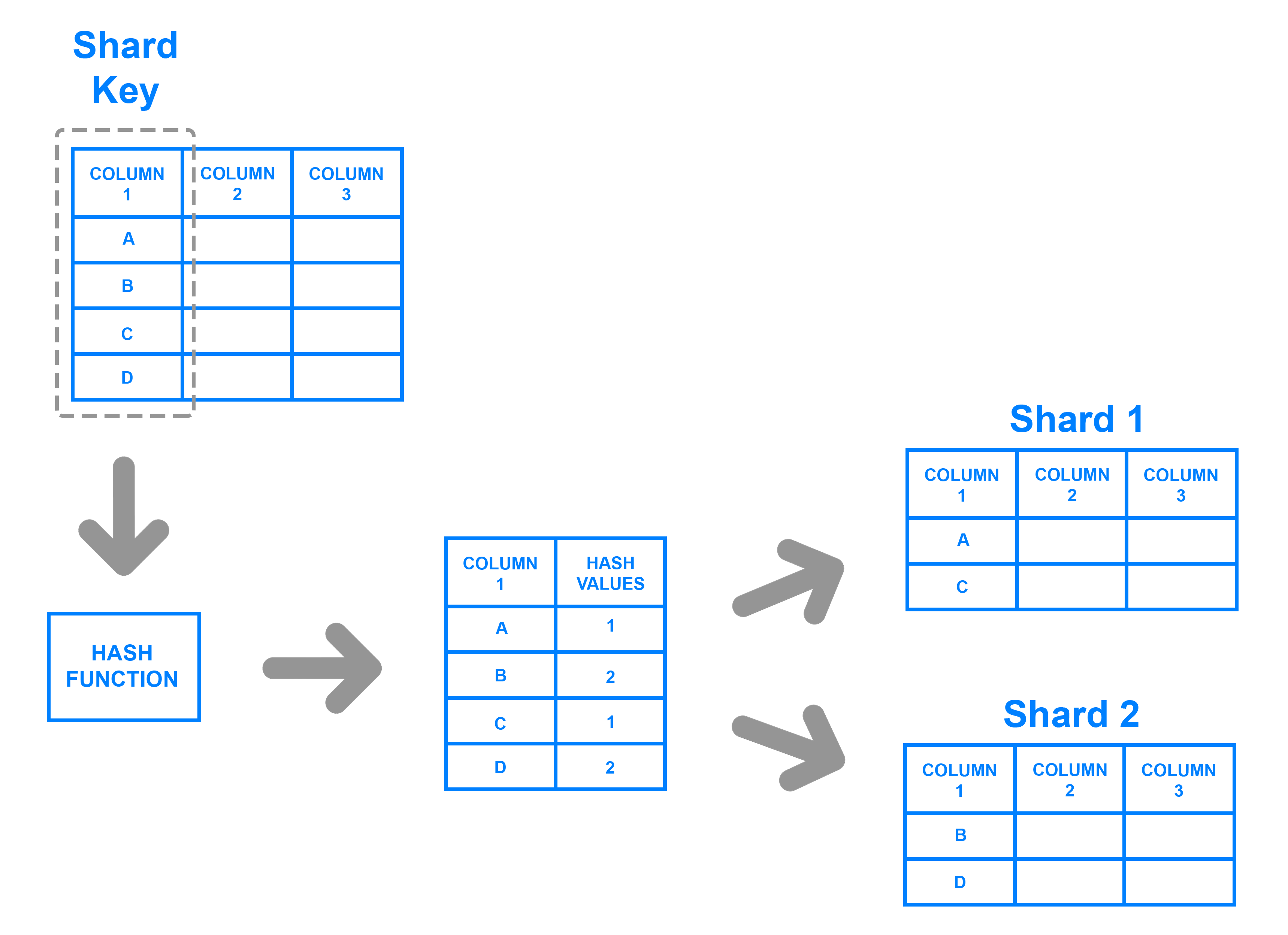
(1)分库分表算法:
先按库取模,再按照表取模
按照总表的数目取模…
计算需要拆分为多少个库表,评估业务量,根据目前环境中的QPS与配置的比例,从而得到需要的实例的数目.
例如:
业务量为最大20万的QPS(其中读、写各占一半),当前环境16核64GB的实例QPS为2万:可拆分为16个库,每个库一个16核64GB实例,这样,最终每个实例的最大QPS的量为20万/16
同时,采用读写分离的方式,添加多个只读节点,分散主库压力
(2)选取分片键
谨慎选择分片键,使业务尽量为分片键上的等值查询。
分片键上的范围查询(应避免)
(3)分表的数目 & 运维复杂度
分库分表,意味着更高的运维复杂度。各种对于子表的操作,都需要完善的流程进行。
(4)子表上的结构变更?怎么验证?
(5)雪花算法生成整型递增主键
(6)数据下游
订阅、同步任务
需要接入多个数据源
离线任务
从不同的数据源进行拉取,再聚合
3.2 数据同步
(1)历史数据迁移
按照分表分库的规则,使用数据库中间价,将数据分批次迁移到目标端。应用常用的分表分库方案有:Sharding-JDBC,对于数据库分库分表中间件,可以用同一产品的分支:Sharding-Proxy。该项目从4.0版本开始,已经收录为了Apache的项目,start的数据也在升高(https://github.com/apache/shardingsphere)。
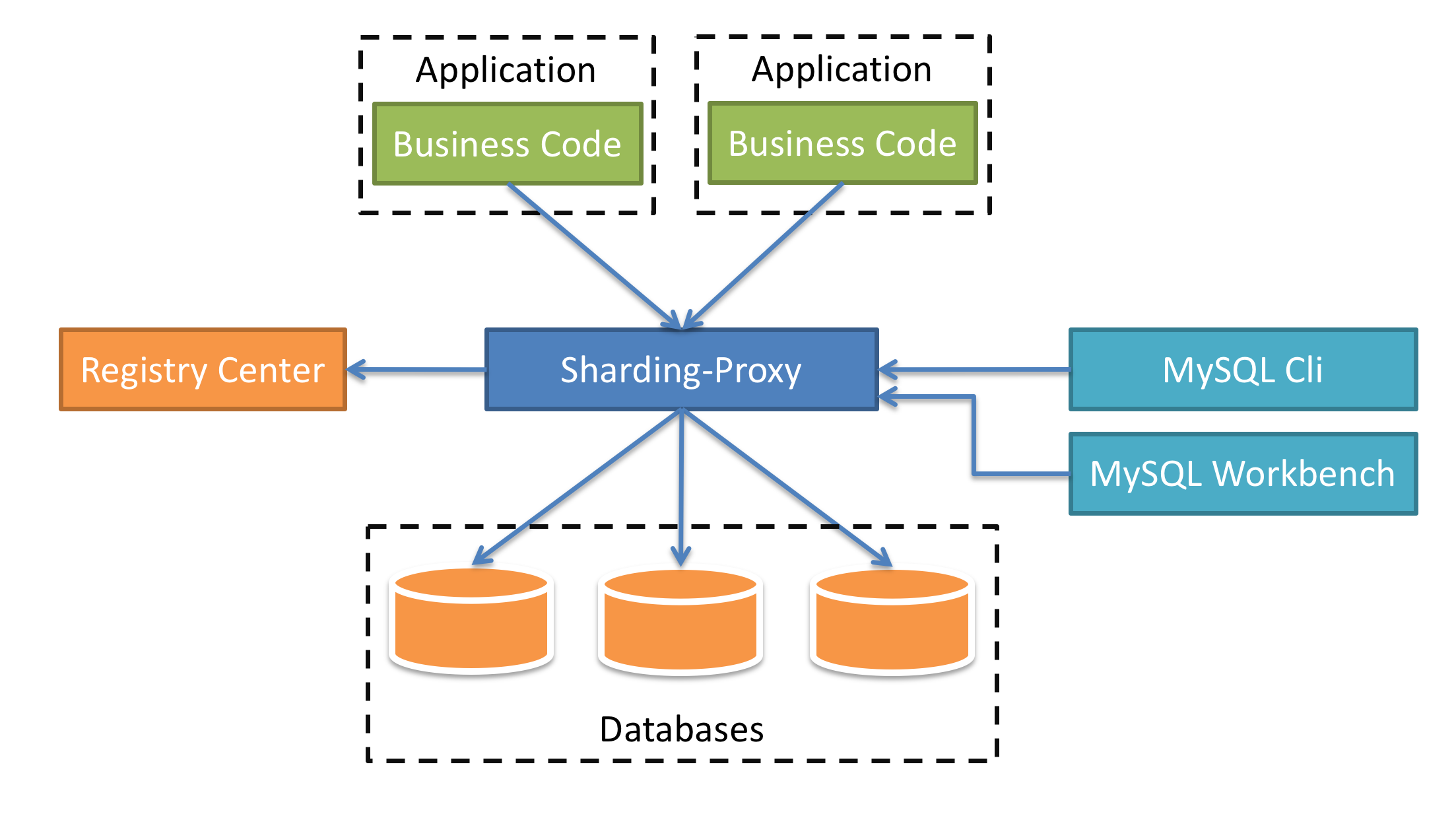
对于Sharding-Proxy,配置数据库分表分库的路由,即可将数据按规则分发到对应的分表中,并且兼容基本的MySQL语法。
全量同步,可直接将数据dump为sql文件,再通过Sharding-Proxy进行回放。
(2)增量同步
在全量数据迁移时,记录下binlog位点,然后从该位点开始进行增量同步,使用binlog订阅的方式,将源端的binlog在目标端回放。
对于源端的数据库配置注意事项,例如:binlog_format=ROW、binlog_row_image=full等的配置项,可参照:http://codercoder.cn/index.php/2020/04/mysql-note-14-attention-when-migrating-data/
对于binlog的同步:
(1)可在源端订阅binlog,解析得到的SQL,在目标端执行
(2)使用同步工具,例如:阿里开源的binlog订阅和消费组件—-canal, MySQL binlog 增量订阅&消费组件;或是阿里的另一个开源项目otter,分布式数据库同步系统
(ps.对比了阿里云、微软云、AWS、腾讯云的数据同步服务,其实哪怕是在商业的解决方案里,阿里云的数据同步方案是灵活性最高,并且兼容性最好的)
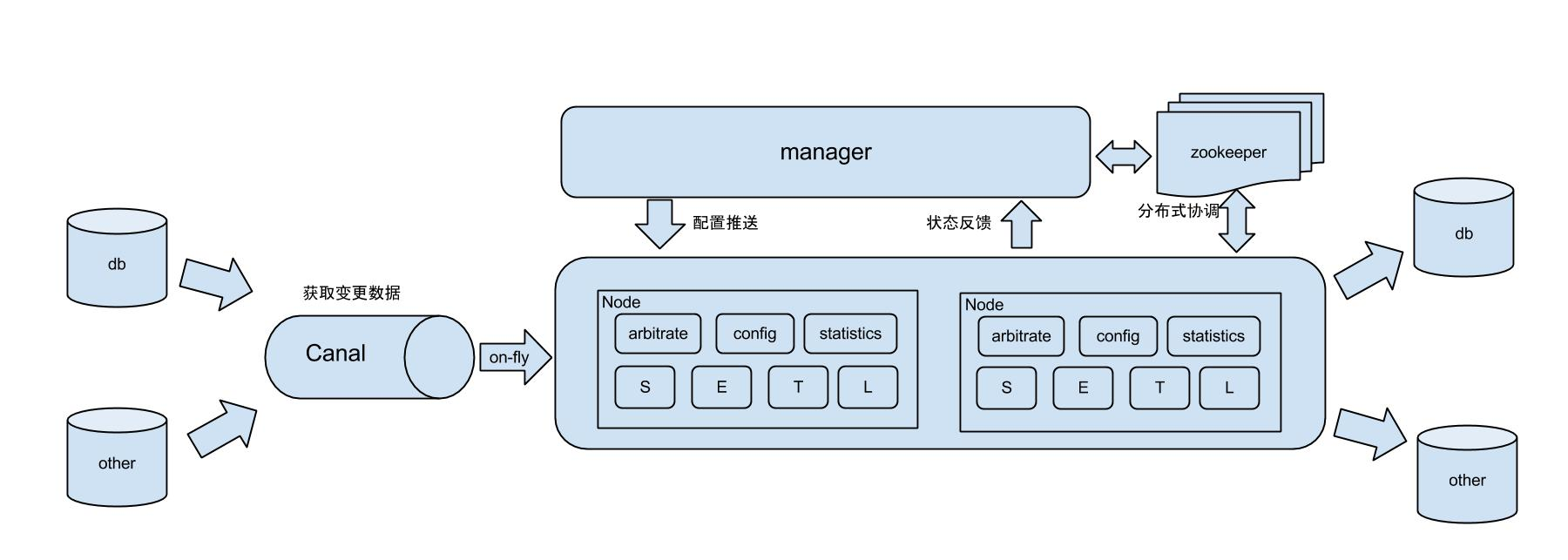
3.3 数据校验
在数据同步后,需要对数据进行校验,常用的方式有:
a.按照主键,分批次逐行对比(效率低,结果精确)
b.对比源端和目标端的数据行数
总结
MySQL的分库分表死活业内常用的数据库拆分手段,能够解决绝大部分的“核心大表”情况。但是分库分表后,若需要进行再次拆分,运维难度就会很大,所以在初期制定时,就要估计好数据量、QPS等的情况,并作出一定冗余。
此外,对于分库分表的运维,由于其复杂度增大,也需要有一套完善的平台进行,降低“人肉运维”出错几率。
若出现了分库分表也支撑不起的业务,那么就可以考虑其它类型的数据库,近年来很火热的分布式数据库不失为一个很好的选择。
后续将会详细介绍“数据同步”、“数据库代理Sharding-Proxy”等内容,敬请期待。
欢迎关注公众号:朔的话:
