

话说上次说把设备状态信息上报到influxDB进行存储,即存储设备的监控信息,既然说了介绍InfluxDB的使用,那这次就按数据库使用维护的角度,介绍下时序数据库InfluxDB。
通常说到数据库会说到库、表、行,这在influxDB中对应database、measurement、point,当然还有时序数据特有的timestamp,以及过期策略:Retention Policy。此外,还有其特别的结构:
Point:Series + timestamp
Series:按照同一个database中,Series = retention policy + measument + tag set相同,即为相同series
Shard:在我们设定Retention Policy的时候,往往就会看到shard关键字,其体现为:一个retention policy下,会根据其设定,拆分为很多个部分,而这些部分,则为shard。
InfluxDB的存储引擎为TSM(从LSM+timestamp演变),每一个SHARD,都对应一个TSM存储引擎,有独立的cache、wal、tsm file。(LSM树结构后续再说,又有下次的主题了:grin:)
https://www.influxdata.com/blog/new-storage-engine-time-structured-merge-tree/
https://docs.influxdata.com/influxdb/v1.8/concepts/storage_engine/
一、常见操作
上次设备监控上报的时候 (文末公众号:涂鸦玩法2 — 设备状态存储展示),简单介绍了如下的SQL:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
$ influx -host 127.0.0.1 -port 8089 -username admin -password 123421
Connected to http://127.0.0.1:8089 version 1.8.1
InfluxDB shell version: 1.8.1
> show databases;
name: databasesname
----
_internal
wstestdb
> use wstestdb
Using database wstestdb
> select time,pir,dev_id from pir_status limit 3;
name: pir_status
time pir dev_id
---- --- ------
1594810825095426778 0 z{Œy{_Z
1594810835293097585 0 z{Œy{_Z
1594810845430362859 1 z{Œy{_Z
此外,influxDB本身也支持http POST的方式进行数据的操作。例如:
插入:
1
2
curl -i -XPOST 'http://localhost:8083/write?db=mydb' --data-binary 'cpu_load_short,host=server02 value=0.67
查询:
1
2
curl -GET 'http://localhost:8086/query?pretty=true' --data-urlencode "db=mydb" --data-urlencode "q=SELECT value FROM cpu_load_short WHERE region='us'"
对于运维人员,需要额外关注一些其它信息。
二、基础运维
2.1 Retention Policy 数据保留策略
(1)创建:
1
2
create RETENTION POLICY "wstestdb_1d" ON "wstestdb" DURATION 1d REPLICATION 1 SHARD DURATION 1d ;
这里可以看到上部分提到的SHARD DURATION,在一个保留策略里,需要设定好过期的时间,还有SHARD的周期,influxDB会按照这个周期拆分、过期数据文件。
(2)修改:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
> show retention policies
name duration shardGroupDuration replicaN default
---- -------- ------------------ -------- -------
autogen 0s 168h0m0s 1 true
> alter RETENTION POLICY "autogen" ON "wstestdb" DURATION 200w REPLICATION 1 SHARD DURATION 1d DEFAULT
> show retention policies
name duration shardGroupDuration replicaN default
---- -------- ------------------ -------- -------
autogen 33600h0m0s 24h0m0s 1 true
通常生产环境中,我们会针对不同类型的measurement,采用不同的retention policy,例如:精度高的表保留3个月,精度低的表保留3年等。
2.2 持续查询 Continuous Queries
InfluxDB深知自己使用的环境,例如在很久以前的数据,大部分用户只关注类似平均值、最大最小值等的情况,而历史的大量数据,会使成本大幅度提高。此时,就出现了持续查询:
1
2
CREATE continuous query cq_30 ON "mydb" RESAMPLE EVERY 15m FOR 60m BEGIN select mean(value) into mean_value from cpu_load_short group by time(30m) END
即把cpu_load_short表的每15分钟平均值,存放在一张新表mean_value中。
这样,Retention Policy加上Continuous Queries,可以在精度和持续性上达到一个平衡。
三、InfluxDB的文件
3.1 文件目录分布
InfluxDB的文件结构较为简单(上次说到,在配置文件中的不同板块进行配置):
data:数据文件目录
meta:数据库元信息
wal:Write Ahead Log目录
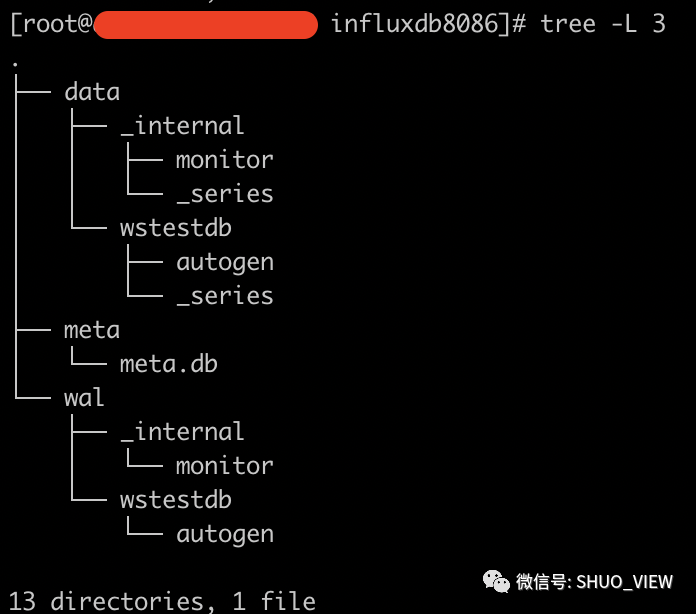
重点关注数据文件目录,更便于我们去理解和使用InfluxDB。
3.2 数据目录
数据目录下,每一个database,分为单独的目录;在不同的database下,不同的retention policy,又分别位于不同的目录下:
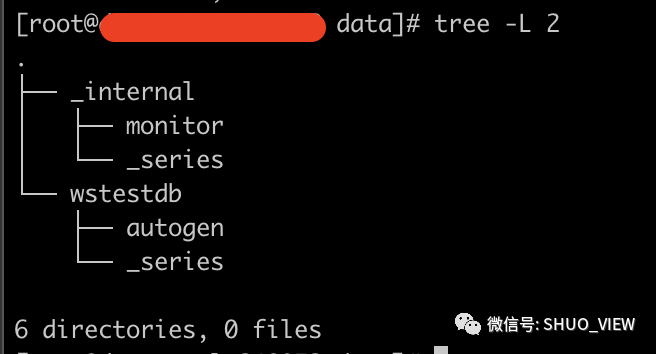
特别注意,“_series”目录,用以存放series索引:
(1)必须在配置中限制series的数目,防止大量的series导致OOM的情况
(2)当series数据太大时,需要及时处理
3.3 Retention Policy与SHARD在文件上的体现
查看_interval库的retention policies:
1
2
3
4
5
6
7
8
> use _internal
Using database _internal
> show retention policies
name duration shardGroupDuration replicaN default
---- -------- ------------------ -------- -------
monitor 168h0m0s 24h0m0s 1 true
对应的文件目录:
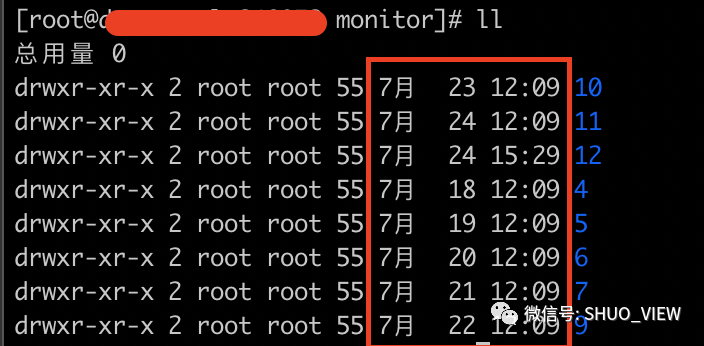
可以看出,文件是按照每24h进行分割的,即Retention Policy中的SHARD DURATION的大小进行,同样,在168h后,将会进行过期处理。
四、InfluxDB的配置
4.1 基础配置
通常我们会修改如下几项:
占用内存的大小:cache-max-memory-size = “2g”
并发查询数:max-concurrent-queries = 1000
慢查询阈值:log-queries-after = “3s”
metadata/数据文件地址:[meta]、[data]中的dir
端口地址:bind-address
4.2 业务实用性配置
根据前三部分的介绍,还需关注:
series相关配置:
例如:max-series-per-database、max-select-series
TSM引擎:
例如:compact-full-write-cold-duration
SHARD相关:
例如:cache-snapshot-write-cold-duration、compact-full-write-cold-duration
timeout相关:
例如:连接超时、查询超时等等
同所有关系型数据库一样,数据库的配置,需要根据业务的使用场景进行适时的调整和优化,已得到更融合的体系。
欢迎关注公众号:朔的话:
