
目的
Group Replication为原生MySQL高可用集群架构,shared-nothing结构。
可以使用Group Replication+Proxy的架构,实现数据库集群的高可用(High Available),参见:ProxySQL_introduction
部署思路
部署文档
Configuring an Instance for Group Replication
安装plugin
所有节点均需要安装
1
2
3
4
5
6
7
8
9
10
11
12
mysql> INSTALL PLUGIN group_replication SONAME 'group_replication.so';
mysql> SHOW PLUGINS;
+----------------------------+----------+--------------------+----------------------+-------------+
| Name | Status | Type | Library | License |
+----------------------------+----------+--------------------+----------------------+-------------+
| binlog | ACTIVE | STORAGE ENGINE | NULL | PROPRIETARY |
(...)
| group_replication | ACTIVE | GROUP REPLICATION | group_replication.so | PROPRIETARY |
+----------------------------+----------+--------------------+----------------------+-------------+
hosts信息
所有节点增加hosts信息在/etc/hosts:
1
2
3
4
172.16.236.81 db-check-001.hc db-check-001
172.16.236.82 db-check-002.hc db-check-002
172.16.236.83 db-check-003.hc db-check-003
172.16.236.84 db-check-004.hc db-check-004
配置项:
在my.cnf文件中,配置Group Replication相关的配置。
group_replication_group_name:GR的名字,格式为全局唯一的UUID,并且所有节点的该项配置相同,
group_replication_single_primary_mode:ON为单主模式。
group_replication_start_on_boot:启动时是否自动打开group_replication。
group_replication_bootstrap_group:是否为第一个启动的节点。
group_replication_enforce_update_everywhere_checks:多主模式的写一致性检查。
If a transaction is executed under the SERIALIZABLE isolation level, then its commit fails when synchronizing itself with the group.
如果事务在SERIALIZABLE隔离级别下执行,则在与组同步时其提交失败。
If a transaction executes against a table that has foreign keys with cascading constraints, then the transaction fails to commit when synchronizing itself with the group.
一个事务如果与含有外键的表级联约束有冲突,则事务在与组同步时无法提交。
group_replication_transaction_size_limit:事务大小限制,单位bytes。
group_replication_auto_increment_increment:自增步长。
group_replication_ip_allowlist:8.0.22开始使用。
group_replication_ip_whitelist:ip白名单,需要加入所有节点的ip。
group_replication_local_address:本地host信息,用以和其它节点通信,不是client的连接地址,格式为:172.16.100.1:13306。
group_replication_group_seeds:所有节点的host信息,不是client的连接地址,格式为:”172.16.100.1:13306,172.16.100.2:13306,172.16.100.3:13306”。
replication_member_weight:选主权重,值越大,权重越高,范围0~100。
default_collation_for_utf8mb4:默认排序规则。
启动
启动原则
(1)若当前集群没有正常ONLINE的节点
需要将第一台节点的group_replication_bootstrap_group设置为ON,start group_replication后再设为OFF。
(2)若当前已经有正常ONLINE的节点
其它节点直接执行start group_replication。
(3)不要配置replicate_wild_ignore_table及同类型的变量
防止出现各个节点数据不一致的情况。
查看状态
集群成员
1
2
3
4
5
6
7
8
9
10
MySQL [(none)]> select * from performance_schema.replication_group_members;
+---------------------------+--------------------------------------+----------------------------+-------------+--------------+-------------+----------------+----------------------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION | MEMBER_COMMUNICATION_STACK |
+---------------------------+--------------------------------------+----------------------------+-------------+--------------+-------------+----------------+----------------------------+
| group_replication_applier | 949538b3-da7d-11ec-9fc0-aa5bf8f34803 | hcdaily-cube-0630-23262.hc | 3306 | ONLINE | PRIMARY | 8.0.27 | XCom |
| group_replication_applier | a38fc9a4-da7d-11ec-b421-92271197a834 | hcdaily-cube-0630-23263.hc | 3306 | ONLINE | SECONDARY | 8.0.27 | XCom |
| group_replication_applier | d4eadf8e-da7c-11ec-b7a6-ba2969388063 | hcdaily-cube-0630-23260.hc | 3306 | ONLINE | SECONDARY | 8.0.27 | XCom |
| group_replication_applier | e4606d62-da7c-11ec-99a8-dab343a6329f | hcdaily-cube-0630-23261.hc | 3306 | ONLINE | SECONDARY | 8.0.27 | XCom |
+---------------------------+--------------------------------------+----------------------------+-------------+--------------+-------------+----------------+----------------------------+
可以看到: MEMBER_ID、MEMBER_PORT、MEMBER_HOST、MEMBER_VERSION:成员信息 MEMBER_STATE:节点状态 MEMBER_ROLE:节点属性PRIMARY/SECONDARY
集群状态
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
MySQL [(none)]> select * from performance_schema.replication_group_member_stats \G
*************************** 1. row ***************************
CHANNEL_NAME: group_replication_applier
VIEW_ID: 16552952942340536:85
MEMBER_ID: 949538b3-da7d-11ec-9fc0-aa5bf8f34803
COUNT_TRANSACTIONS_IN_QUEUE: 0
COUNT_TRANSACTIONS_CHECKED: 1494714
COUNT_CONFLICTS_DETECTED: 0
COUNT_TRANSACTIONS_ROWS_VALIDATING: 14
TRANSACTIONS_COMMITTED_ALL_MEMBERS: 9be359f4-540d-11ec-8145-5ea8bb8042cd:1-6093609:6893564-6893608:7893564-7893565
LAST_CONFLICT_FREE_TRANSACTION: 9be359f4-540d-11ec-8145-5ea8bb8042cd:6093717
COUNT_TRANSACTIONS_REMOTE_IN_APPLIER_QUEUE: 1
COUNT_TRANSACTIONS_REMOTE_APPLIED: 1400937
COUNT_TRANSACTIONS_LOCAL_PROPOSED: 93784
COUNT_TRANSACTIONS_LOCAL_ROLLBACK: 0
可以看到: MEMBER_ID:节点ID TRANSACTIONS_COMMITTED_ALL_MEMBERS:节点执行的事务信息
延迟情况
若节点处于RECOVERY状态,则其可能产生了延迟,查看延迟情况。
在正常节点和异常的节点,分别执行:
1
2
3
4
5
6
7
8
9
10
11
12
mysql> show variables like "%gtid_executed%";
+----------------------------------+--------------------------------------------------------------------------------+
| Variable_name | Value |
+----------------------------------+--------------------------------------------------------------------------------+
| gtid_executed | 9be359f4-540d-11ec-8145-5ea8bb8042cd:1-6392371:6893564-6893608:7893564-7893565 |
| gtid_executed_compression_period | 0 |
+----------------------------------+--------------------------------------------------------------------------------+
2 rows in set (0.00 sec)
或者:
mysql> show master status;
可以通过gtid_executed的事务数,查看延迟的情况。
注意:
可配置为延迟超过N个事务,则通过clone重新同步数据,可参见group_replication_clone_threshold参数:
若延迟事务数超过这个配置,就会使用远程clone重新同步数据。 group_replication_clone_threshold
worker状态
The replication channels created by the Group Replication plugin are named:
(1) group_replication_recovery
This channel is used for the replication changes that are related to the distributed recovery phase.
此通道用于与分布式恢复阶段相关的复制更改。
(2) group_replication_applier
This channel is used for the incoming changes from the group. This is the channel used to apply transactions coming directly from the group.
此通道用于接收来自组的传入更改。这是直接应用来自组的事务的通道。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
mysql> select * from performance_schema.replication_applier_status_by_worker limit 1 \G
*************************** 1. row ***************************
CHANNEL_NAME: group_replication_applier
WORKER_ID: 1
THREAD_ID: 112
SERVICE_STATE: ON
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00.000000
LAST_APPLIED_TRANSACTION: 9be359f4-540d-11ec-8145-5ea8bb8042cd:5383177
LAST_APPLIED_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP: 2023-06-29 08:20:11.918716
LAST_APPLIED_TRANSACTION_IMMEDIATE_COMMIT_TIMESTAMP: 2023-06-29 08:20:11.918716
LAST_APPLIED_TRANSACTION_START_APPLY_TIMESTAMP: 2023-06-29 08:20:11.919354
LAST_APPLIED_TRANSACTION_END_APPLY_TIMESTAMP: 2023-06-29 08:20:11.922030
APPLYING_TRANSACTION:
APPLYING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP: 0000-00-00 00:00:00.000000
APPLYING_TRANSACTION_IMMEDIATE_COMMIT_TIMESTAMP: 0000-00-00 00:00:00.000000
APPLYING_TRANSACTION_START_APPLY_TIMESTAMP: 0000-00-00 00:00:00.000000
LAST_APPLIED_TRANSACTION_RETRIES_COUNT: 0
LAST_APPLIED_TRANSACTION_LAST_TRANSIENT_ERROR_NUMBER: 0
LAST_APPLIED_TRANSACTION_LAST_TRANSIENT_ERROR_MESSAGE:
LAST_APPLIED_TRANSACTION_LAST_TRANSIENT_ERROR_TIMESTAMP: 0000-00-00 00:00:00.000000
APPLYING_TRANSACTION_RETRIES_COUNT: 0
APPLYING_TRANSACTION_LAST_TRANSIENT_ERROR_NUMBER: 0
APPLYING_TRANSACTION_LAST_TRANSIENT_ERROR_MESSAGE:
APPLYING_TRANSACTION_LAST_TRANSIENT_ERROR_TIMESTAMP: 0000-00-00 00:00:00.000000
1 row in set (0.01 sec)
展示了复制线程的:
- 最后一次执行的事务号、时间戳等信息
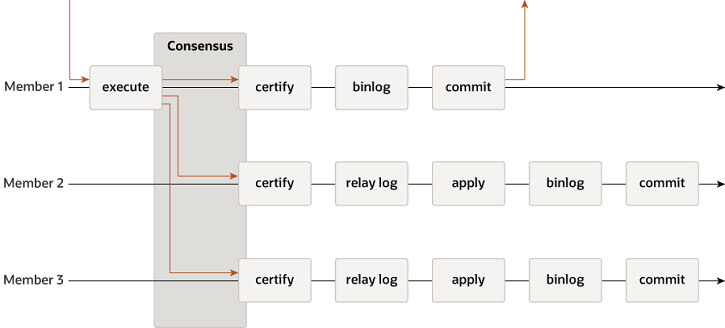
事务一致性控制
对于read-write事务,投递更新的行及其对应的write sets值。
certification的定义: However, there may be conflicts between transactions that execute concurrently on different servers. Such conflicts are detected by inspecting and comparing the write sets of two different and concurrent transactions, in a process called certification.
数据冲突
transaction_write_set_extraction
默认:XXHASH64。写事务的提取算法,用来检测冲突。
transaction_write_set_extraction must not be OFF. While the current value of binlog_transaction_dependency_tracking is WRITESET or WRITESET_SESSION, you cannot change the value of transaction_write_set_extraction.
binlog_transaction_dependency_tracking
默认:COMMIT_ORDER。再多线程复制时候的依赖原则(代表源端写入时候的logical timestamps)。 注意: replica_parallel_type、slave_parallel_type需要设置为LOGICAL_CLOCK
(1)多线程复制
- replica_parallel_workers
- slave_parallel_workers
(2)logical timestamps:
- sequence_number:按照1,2,3的顺序,逐渐递增
- last_committed:总是小于sequence_number,指与当前事务冲突的最近提交事务的序列号。
(3)COMMIT_ORDER Two transactions are considered to be independent if the commit-time window of the first transaction overlaps with the commit-time window of the second transaction. This the default.
默认选项。如果第一个事务的提交时间窗口与第二个事务的提交时间窗口重叠,则认为两个事务是独立的。
The commit-time window begins immediately following the execution of the last statement of the transaction, and ends immediately after the storage engine commit ends. Since transactions hold all row locks between these two points in time, we know that they cannot update the same rows.
上一个事务结束后,提交时间窗口马上开始,并且在存储引擎提交后立刻结束。因为事务在此期间获得行的锁,所以我们认为事务不会更新相同的行。
(4)WRITESET Logical timestamps are computed based on COMMIT_ORDER in combination with a second scheme based on write sets for the transaction. Each row in the transaction adds a set of one or more hashes to the transaction’s write set, one of each unique key in the row. (If there are no unique, nonnullable keys, a hash of the row is used.) This includes both deleted and inserted rows; for updated rows, both the old and the new row are also included.
WRITESET: 逻辑时间戳基于COMMIT_ORDER结合事务write set进行计算。在事务的write set集中,每一行增加一个或者多个hash值,行中的每个唯一键之一。(若没有唯一、非空的键,row的hash值将被使用)报错insert\delete,对于update,还包括新的行和旧的行。
Two transactions are considered conflicting if their write sets overlap—that is, if there is some number (hash) that occurs in the write sets of both transactions.
若两个事务的write set相同,则认为他们冲突,即两个事务中的hash值相同。
(5)WRITESET_SESSION Two transactions are considered dependent if either of the following statements is true:
- The transactions are dependent according to WRITESET.
- The transactions were committed in the same user session.
一个既符合WRITESET的规则,并且在同一个用户session中提交,则为WRITESET_SESSION。
(6)序列化点的产生: In addition, due to the way the write sets are computed, there are periodic serialization points, such that the write set computation process regards every transaction after a serialization point as conflicting with every transaction before the serialization point. Serialization points affect only dependencies computed by the WRITESET algorithm; transactions on opposite sides of the serialization point may have overlapping commit-time windows, and so can be parallelized on replica in spite of this. Serialization points occur for DDL statements, for transactions updating a table having a foreign key, and for transactions where the session value of transaction_write_set_extraction is not the same as the global value. A serialization point is also imposed if the transactions committed since the previous serialization point have generated a total of at least binlog_transaction_dependency_history_size unique hashes.
此外,由于write set的计算方式,存在周期性的序列化位点,这样的write set计算过程将序列化点之后的每个事务视为与序列化点之前的每个事务冲突。
序列化点仅仅影响使用WRITESET算法计算的;序列化点两侧的事务可能具有重叠的提交时间窗口,所以在并发复制时可忽略。
DDL、更新有外键的表、或者session级别的transaction_write_set_extraction与全局不一样的事务,均会产生序列化点。
如果自上一个序列化点以来提交的事务总共生成了至少 binlog_transaction_dependency_history_size个唯一哈希值,则也会施加一个序列化点。
数据一致性
group_replication_consistency
可以参考文章进行理解:Making Sense of MySQL Group Replication Consistency Levels
(1)EVENTUAL Both RO and RW transactions do not wait for preceding transactions to be applied before executing. This was the behavior of Group Replication before this variable was added. A RW transaction does not wait for other members to apply a transaction. This means that a transaction could be externalized on one member before the others. This also means that in the event of a primary failover, the new primary can accept new RO and RW transactions before the previous primary transactions are all applied. RO transactions could result in outdated values, RW transactions could result in a rollback due to conflicts.
RO和RW事务均不等待前序事务的回放。即老的PRIMARY宕机后,新的PRIMARY可以直接执行RO和RW事务。
RO:可能读到历史版本的数据
RW:数据冲突导致回滚
(2)BEFORE_ON_PRIMARY_FAILOVER New RO or RW transactions with a newly elected primary that is applying backlog from the old primary are held (not applied) until any backlog has been applied. This ensures that when a primary failover happens, intentionally or not, clients always see the latest value on the primary. This guarantees consistency, but means that clients must be able to handle the delay in the event that a backlog is being applied. Usually this delay should be minimal, but does depend on the size of the backlog.
在原PRIMARY的事务回放结束之前,阻塞新的RO和RW事务。这保证了主库宕机时,总是读取到最新的数据。
保证一致性,但是需要能够容忍回放完成前的阻塞。
(3)BEFORE A RW transaction waits for all preceding transactions to complete before being applied. A RO transaction waits for all preceding transactions to complete before being executed. This ensures that this transaction reads the latest value by only affecting the latency of the transaction. This reduces the overhead of synchronization on every RW transaction, by ensuring synchronization is used only on RO transactions. This consistency level also includes the consistency guarantees provided by BEFORE_ON_PRIMARY_FAILOVER.
RW:在applay之前,等待所有前序事务完成
RO:在执行之前,等待所有前序事务完成
通过影响事务的延迟来保证读取到最新数据。
通过同步只用于RO事务,减少了RW事务的同步瓶颈。
包含了BEFORE_ON_PRIMARY_FAILOVER的一致性保证。
(4)AFTER A RW transaction waits until its changes have been applied to all of the other members. This value has no effect on RO transactions. This mode ensures that when a transaction is committed on the local member, any subsequent transaction reads the written value or a more recent value on any group member. Use this mode with a group that is used for predominantly RO operations to ensure that applied RW transactions are applied everywhere once they commit. This could be used by your application to ensure that subsequent reads fetch the latest data which includes the latest writes. This reduces the overhead of synchronization on every RO transaction, by ensuring synchronization is used only on RW transactions. This consistency level also includes the consistency guarantees provided by BEFORE_ON_PRIMARY_FAILOVER.
RW:等待直到变更已经被所有的节点apply
RO:无影响
保证了一旦RW事务在本地提交,则所有节点均能够读到最新的数据。 (可以在主要是RO事务的场景使用。)
减少了RO事务的同步瓶颈。包括了BEFORE_ON_PRIMARY_FAILOVER一致性保证。
(5)BEFORE_AND_AFTER A RW transaction waits for 1) all preceding transactions to complete before being applied and 2) until its changes have been applied on other members. A RO transaction waits for all preceding transactions to complete before execution takes place. This consistency level also includes the consistency guarantees provided by BEFORE_ON_PRIMARY_FAILOVER. RW:在applyz之前,等待所有前序事务 直到变更被所有节点apply。
RO:在执行前,等待所有前序事务回放结束 同样包括BEFORE_ON_PRIMARY_FAILOVER的数据一致性保证。
group_replication_consistency举例
(1) Eventual:
- 不影响RW写入耗时
- 不影响RO读取耗时,会读取到历史版本数据
(2) Before:
- 不影响RW写入耗时
- RO读取耗时变长,因为RO节点需要等待事务写入成功后,才能读取
(3) After:
- 影响RW的写入耗时,因为RW节点需要等待所有节点写入成功,才能写入
- 不影响RO读取耗时
常见问题
调优思路
- (1)查看集群状态
- (2)任何MySQL系统变量的变更,均需要分别登录到各个节点上进行
- (3)慢查日志需要分别查看
- (4)避免做set read_only=off的操作,因为重新加入到集群后,需要检测冲突并修复
故障处理
(1)集群宕机 根据启动的原则,逐一启动集群。
(2)先启动的节点为SECONDARY节点 则先启动的节点为SECONDARY节点,报错的节点为PRIMARY节点。
在所有节点stop group_replication,然后再根据启动的原则,逐一启动集群。
(3)relay log文件损坏 在报错的节点重置relay log:
1
2
stop group_replication;
RESET SLAVE ALL FOR CHANNEL "group_replication_applier";
(4)指定节点为PRIMARY SELECT group_replication_set_as_primary(“2b9ac943-a8e7-11ec-bad8-caff96ced67b”);
前提: replication_group_members表中的所有节点的状态都要为“ONLINE”,否则报错:ERROR 1123 (HY000): Can’t initialize function ‘group_replication_set_as_primary’; A member is joining the group, wait for it to be ONLINE.
延迟太大
若延迟过大,可尝试重新通过远程clone同步数据
多线程复制
- replica_parallel_workers
- slave_parallel_workers
降低IO的消耗
通过降低relay log的刷盘操作,参考:sync_relay_log
(1)sync_relay_log If the value of this variable is greater than 0, the MySQL server synchronizes its relay log to disk (using fdatasync()) after every sync_relay_log events are written to the relay log. Setting this variable takes effect for all replication channels immediately, including running channels.
(2)sync_relay_log_info
- sync_relay_log_info = 0 If relay_log_info_repository is set to FILE, the MySQL server performs no synchronization of the relay-log.info file to disk; instead, the server relies on the operating system to flush its contents periodically as with any other file.
If relay_log_info_repository is set to TABLE, and the storage engine for that table is transactional, the table is updated after each transaction. (The sync_relay_log_info setting is effectively ignored in this case.)
If relay_log_info_repository is set to TABLE, and the storage engine for that table is not transactional, the table is never updated.
- sync_relay_log_info = N > 0 If relay_log_info_repository is set to FILE, the replica synchronizes its relay-log.info file to disk (using fdatasync()) after every N transactions.
If relay_log_info_repository is set to TABLE, and the storage engine for that table is transactional, the table is updated after each transaction. (The sync_relay_log_info setting is effectively ignored in this case.)
If relay_log_info_repository is set to TABLE, and the storage engine for that table is not transactional, the table is updated after every N events.