
The Question
Recently when i talked with my workmate about how to select the max() row with the primary key of a MySQL table, it’s normal to write the query like:
1
select max(point), id from tb;
Although you can get the right max(point) after the command is executed, the primary key, id, is wrong in the result.
For the correct result, we can write it as:
1
select point, id from tb order by point desc limit 1;
Even in a subquery way:
1
select max(point), id from tb where point in (select max(point) from tb);
The subquery way is more dangerous when there is no index on the point column, because it will examine the table twice.
Why?
But why can’t we use the “max(point), id” to get the additional columns?
For common sense, if we get the wrong result of the command, there must be like:
- The query is wrong. (But why MySQL doesn’t show any warnings?)
-
It’s a MySQL BUG or LIMITATION
- Then i searched this question, there are many people are curious about it:
https://www.mysqltutorial.org/mysql-aggregate-functions/mysql-max-function/
https://teamtreehouse.com/community/getting-the-primary-key-of-the-row-with-the-maximum-value
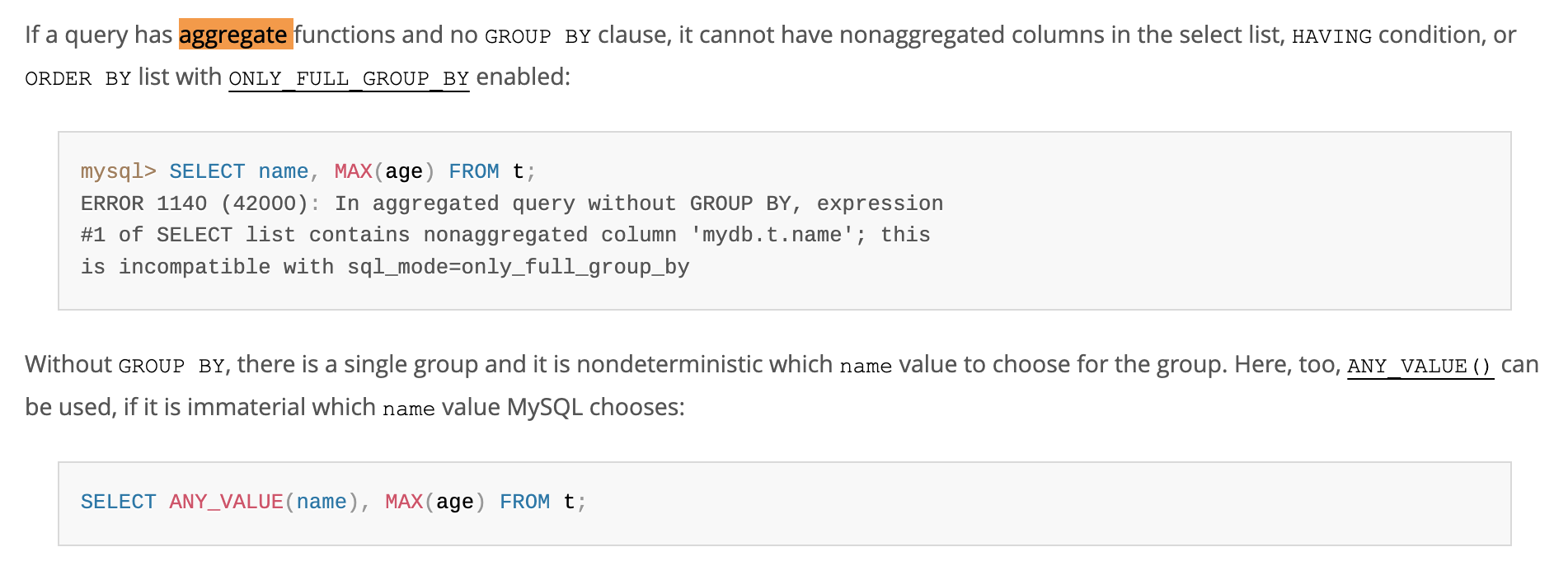
Then i read the MySQL Reference Manual, it shows that “Without GROUP BY, there is a single group and it is nondeterministic which name value to choose for the group.”
https://dev.mysql.com/doc/refman/8.4/en/group-by-handling.html
The Reason
It’s becoming clear, first of all, we didn’t set the sql_mode to “ONLY_FULL_GROUP_BY”, which can help to reject queries for this no GROUP BY situation, especially queries with the Aggregate Function.
So the column with no group by in the result is nondeterministic.