
一、提要
对DBA来说,数据迁移可能是维护工作中最常见的操作了,很多场景,都需要进行数据的迁移,所以需要总结一套迁移的流程,按照既定的流程进行操作。本篇主要是阐述一些迁移过程中的注意事项,后续将逐渐介绍迁移的方案。
数据库的迁移,涉及到运维团队、开发团队,在进行之前,一定要协调好相关的人员。在这个过程中,极有可能出现一些问题(从第二部分就可以看出“坑”是相当多的),需要及时反馈。
参考步骤:
1.业务方发起数据库迁移申请:
新建群,拉取DBA和相关的人员(特别是数据涉及到的业务方人员和大数据人员,注意一个库表,多个应用使用的情况)
2.业务方和上述人员确认数据库、表,是否有订阅或者定时离线任务
3.DBA开启同步通道,待同步延迟在1s以内时:
有订阅或者离线任务:业务方群里通知订阅人员修改数据源
没有订阅或者离线任务:修改数据源配置
4.DBA通知应用方读取新的配置
5.DBA观察发布连接情况,待全部发布后,释放同步连接(通常会等待3天左右的时间,观察无流量后释放,防止部分离线任务未进行切换)
6.业务方申请下线老的数据源
7.DBA验证原实例无连接,3日之内审计没有对应库、表的访问后,备份并下线库表
二、注意事项
2.1 防止踩“坑”
上部分说到的每一步,几乎都存在各式各样的“坑”,但是,如果去避免?
(1)DBA本身对于整个流程的把控
(2)在迁移之前的全链路测试
(3)数据一致性的验证
(4)可能发生的情况的预测
2.2 花样“踩坑”
(1)流程发起
流程发起通常需要和开发确认,开发人员对于业务的需求,都会比DBA更为了解。公司若有条件,可以开发平台,用来统计和管理数据的流向,便于数据的管控。
(2)离线任务、订阅等的确认
需要有相关的记录,防止出现“背锅”现象。而且对于流程管理来说,每一步都有对应的记录和对接的人员,更会让技术流程更加标准化。
(3)同步通道的延迟
DBA需要提前部署,根据数据量已经binlog产生的速度,建立合理规格的同步通道:
(何为合适?主要从以下两个方面进行评估:
a.数据量的大小:判断全量拉取完全部的数据,需要的耗时时间,尽量使全量同步在3天内完成,并且越短时间越好,因为生产环境中,binlog往往不会全量保存,会有过期时间。所以,如果全量同步很慢,则增量的binlog可能已经过期,导致同步失败
b.binlog产生的速度:例如创建的同步通道最高只能达到3000QPS,若源端产生的binlog速度大于3000QPS,则目标端会永远追不上源端,导致同步失败
)
所以选择同步通道的大小,也是关键的一步。
1
2
3
对于阿里云DTS(Data Transmission Service):按照同步通道的不同规格进行收费,不同的规则对应不同的QPS大小
对于亚马逊DMS(Database Migration Service):同步通道为一个实例,购买相应大小的实例,再在实例上进行传输服务
各个同步的工具,几乎都会反应同步的延迟情况。DBA需要进行关注。
(4)数据一致性
涉及到数据的同步,往往有这样的问题,就是怎么防止两端的数据不一致?什么情况会导致不一致的情况?怎么去验证?
对于验证数据一致性的工具很多,例如:MySQL手记13 — 使用mysqldbcompare对比数据一致性,也有既定的对比思路可以进行自己开发,例如需要怎么对比数据,对比多少的数据量,每次对比多少量等等。
(5)回滚
对于回滚,也非常有讲究,什么样的情况需要回滚?为了回滚,需要DBA前期做什么工作?等等之类的情况,都需要进行测试和模拟。
三、同步通道类型
3.1 同步通道
目前的通用的方法都是通过实时订阅binlog消息进行的同步。之前提到过,有阿里云的DTS、亚马逊的DMS、腾讯云的数据迁移服务相比之下灵活性不如阿里云DTS和亚马逊DMS(但是腾讯云的迁移服务目前是免费的2020-04-28)。
同样,也可以使用自建的数据库同步通道,开源的产品有:canal(阿里巴巴)、Otter(基于canal做的产品)、Syncer(PingCAP公司开发的同步工具)
3.2 单向同步
单向同步往往适用于不需要回滚的场景:应用跳转到目标段后,若产生了数据,则这部分数据已经落实在目标端,所以若需要回滚,则这部分数据难以重新同步到源端(会耗费巨大运维资源)
单向同步的好处在于:场景即情况简单,几乎不会出问题,就类似与MySQL本身的主从,属于比较稳定、常见的解决方案。
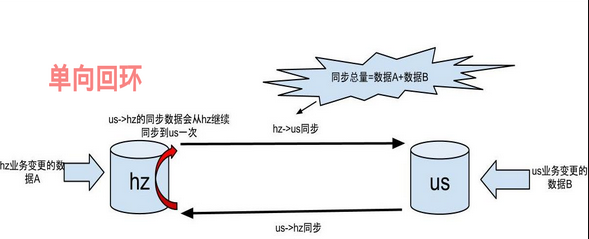
3.3 双向同步
双向同步需要考虑的问题就很多,例如“数据回环”的问题。Otter工具,对于“数据回环”就给出了自己的解决方案:https://github.com/alibaba/otter/wiki/Otter%E6%95%B0%E6%8D%AE%E4%B8%80%E8%87%B4%E6%80%A7
优点:
对于很对核心的业务,为了防止在切换时出现问题,所以都需要做兜底的方案。那么双向同步就是一个不错的选择:
在应用切到目标端后,若出现异常需要回滚,那么在目标端进行的变更,同样会实时同步到源端,业务切回时,就能有一致的数据。
由于双向同步是非常重要的,甚至是非常必要的,所以,在部署使用双向同步之前,一定要做足充分的测试。特别是“数据一致性”的测试,不然双向同步会让整一个的运维难度和业务切换进入到一个非常复杂的局面。
控制数据的流向,在整个双向同步的过程尤为重要,DBA也必须通过现想去看到本质,数据是怎么流的,binlog里到底记录了什么信息,如果需要回滚,怎么去使用binlog查找到错误或者冲突的数据,数据冲突时候,怎么去解决……
亚马逊DMS:
https://aws.amazon.com/cn/dms/faqs/

四、数据一致性
数据一致性,是整个数据库迁移过程中的难点,需要DBA对整个链路都有非常严格和熟练的把控,一环出问题,后果不堪设想。(例如,在数据冲突上出问题,如果有一行数据除了问题,那么除了后续数据也会受影响以外,同步通道会整个堵住,应用也会出现相应的报错,写入的数据查询不到,导致灾难性问题)
4.1 测试同步通道
同步通道搭建起来后,需要进行测试,可以使用Sysbench工具进行。在两端分别/同时插入和更新数据,对比两边的数据是否一致。MySQL手记4 — Sysbench进行QPS性能测试
4.2 双写(两端同时写入)
(1)两端并发insert自增问题
(2)两端并发update唯一索引问题
…
后续文章会全面展开双写的测试,及如何避免出现数据不一致的情况
五、确认数据迁移成功
应用切换完成后,DBA需要根据原实例和目标实例的:
连接情况:判断原实例是否有连接,目标实例的连接数是否正常
SQL执行情况:可以根据审计日志、慢查、general log等日志查看原实例上是否仍有SQL的执行
完成后,还需要保留同步通道和原实例,防止部分应用遗漏的情况。
欢迎关注公众号:朔的话:
